Redis(四)线程模型
Redis单线程的含义
Redis 单线程指的是「接收客户端请求->解析请求 ->进行数据读写等操作->发生数据给客户端」(网络 IO 以及键值对指令读写是由一个线程来执行的)这个过程是由一个线程(主线程)来完成的,这也是我们常说 Redis 是单线程的原因。
但实际还有一些后台线程(BIO)用于执行一些比较耗时的操作。
后台线程相当于一个消费者,生产者把耗时任务丢到任务队列中,消费者(BIO)不停轮询这个队列,拿出任务就去执行对应的方法即可。
关闭文件、AOF 刷盘、释放内存这三个任务都有各自的任务队列:
- BIO_CLOSE_FILE,关闭文件任务队列:当队列有任务后,后台线程会调用 close(fd) ,将文件关闭;
- BIO_AOF_FSYNC,AOF 刷盘任务队列:当 AOF 日志配置成 everysec 选项后,主线程会把 AOF 写日志操作封装成一个任务,也放到队列中。当发现队列有任务后,后台线程会调用 fsync(fd),将 AOF 文件刷盘;
- BIO_LAZY_FREE,lazy free 任务队列:当队列有任务后,后台线程会 free(obj) 释放对象 / free(dict) 删除数据库所有对象 / free(skiplist) 释放跳表对象。
Redis 单线程模式怎么实现的?
在 Linux 系统上 Redis 采用了 epoll 和 Reactor 结合的 IO 模型,非常高效。
epoll 模型
简单来说就是 epoll 会帮你管着一大堆的套接字。每次你需要做啥的时候,就问问哪些套接字可用。读数据,就是找出那些已经收到了数据的套接字;写数据,就是找出那些可以写入数据的套接字。而在 Linux 系统里面,套接字就是一个普通的文件描述符,因此 epoll 本质上是管着一堆文件描述符。
epoll 里面有两个关键结构:
- 一个是红黑树,每一个节点都代表了一个文件描述符;
- 一个是双向链表,也叫做就绪列表。
为了维护 epoll 的结构,有三个关键的系统调用:
- epoll_create:也就是创建一个 epoll 结构
- epoll_ctl:管理 epoll 里面的那些文件描述符,简单说就是增删改 epoll 里面的文件描述符。
- epoll_wait:根据你的要求,返回符合条件的文件描述符,也就是查。
发起epoll调用
当你发起 epoll_wait 的时候,有两种情况:
第一种情况是就绪列表里面有符合条件的套接字,直接给你;
第二种情况就是就绪列表里面没有符合条件的套接字,这时候传入不同的超时时间,会有不同的响应。-1 永远阻塞,0 立刻返回,正数等待直到超时。
Note亮点:就是 epoll 怎么知道数据来了?又或者 epoll 怎么知道超时了?
答案是中断。
每一个和 IO 有关的文件描述符都有一个对应的驱动,这个驱动会告诉 epoll 发生了什么。比如说,当有数据发送到网卡的时候,会触发一个中断。借助这个中断,网卡的驱动会告诉 epoll,这里有数据了。而超时也是利用了中断,不过是时钟中断。时钟中断之后,内核会去检查发起 epoll_wait 的线程有没有超时,如果超时了就会唤醒这个线程。调用者就会得到超时响应。
epoll和 poll 、select 区别: epoll 会提前帮你准备好符合条件的文件描述符,但是 select 不会 ,你必须要发起 select 调用,内核才会一个个帮你问 ,poll和seclect原理一样
Redis会根据编译平台的不同选择不同的 I/O 多路复用函数作为子模块,提供给上层统一的接口;
在 Redis 中,我们通过宏定义的使用,合理的选择不同的子模块:
#ifdef HAVE_EVPORT#include "ae_evport.c"#else
#ifdef HAVE_EPOLL
#include "ae_epoll.c"
#else
#ifdef HAVE_KQUEUE
#include "ae_kqueue.c"
#else
#include "ae_select.c"
#endif
#endif
#endif因为 select 函数是作为 POSIX 标准中的系统调用,在不同版本的操作系统上都会实现,所以将其作为保底方案
Reactor 模式
Reactor 模式:一个分发器 + 一堆处理器
一般来说,客户端和服务端的 IO 交互主要有两类事件:连接事件和读写事件。那么 Reactor 里面的分发器就是把连接事件交给 Acceptor,把读写事件交给对应的 Handler。这些 Handler 最终会调用到你真正需要读写数据的业务代码。
整体工作流程
Redis 是单线程模型,所以 Reactor、Handler 和 Acceptor 其实都是这个线程。
整个过程是这样的:
Redis 中的 Reactor 调用 epoll,拿到符合条件的文件描述符;
假如说 Redis 拿到了可读写的描述符,就会执行对应的读写操作;
如果 Redis 拿到了创建连接的文件描述符,就会完成连接的初始化,然后准备监听这个连接上的读写事件。
后面在 6.0 的时候,Redis 改成了多线程模型,但是基本原理还是 Reactor + epoll。

Redis 6.0 之前为什么使用单线程?
从投入产出来看。
首先如果引入多线程,主要是希望充分利用多核的性能,但Redis的定位,是内存k-v存储,是做短平快的热点数据处理,一般来说执行会很快,执行本身不应该成为瓶颈,而瓶颈通常在网络I/O,处理逻辑多线程并不会有太大收益。同时,支持多线程的话,我们需要付出更大的复杂度、以及多线程上下文切换、同步机制的开销等成本。
这样综合来看,成本高且收益不大,所以最终选择了不做,事实也证明,单线程的Redis也确实足够高效
CPU 并不是制约 Redis 性能表现的瓶颈所在,更多情况下是受到内存大小和网络 I/O 的限制
Redis单线程性能如何
Redis单线程的性能是很好的,在普通机器每秒能10多万的读性能、几万的写性能。
Redis 6.0 之后为什么引入了多线程?
随着硬件性能提升,Redis 的性能瓶颈可能出现网络 IO 的读写,也就是:单个线程处理网络读写的速度跟不上底层网络硬件的速度。
读写网络的 read/write 系统调用占用了Redis 执行期间大部分CPU 时间,瓶颈主要在于网络的 IO 消耗。
Redis多线程模型
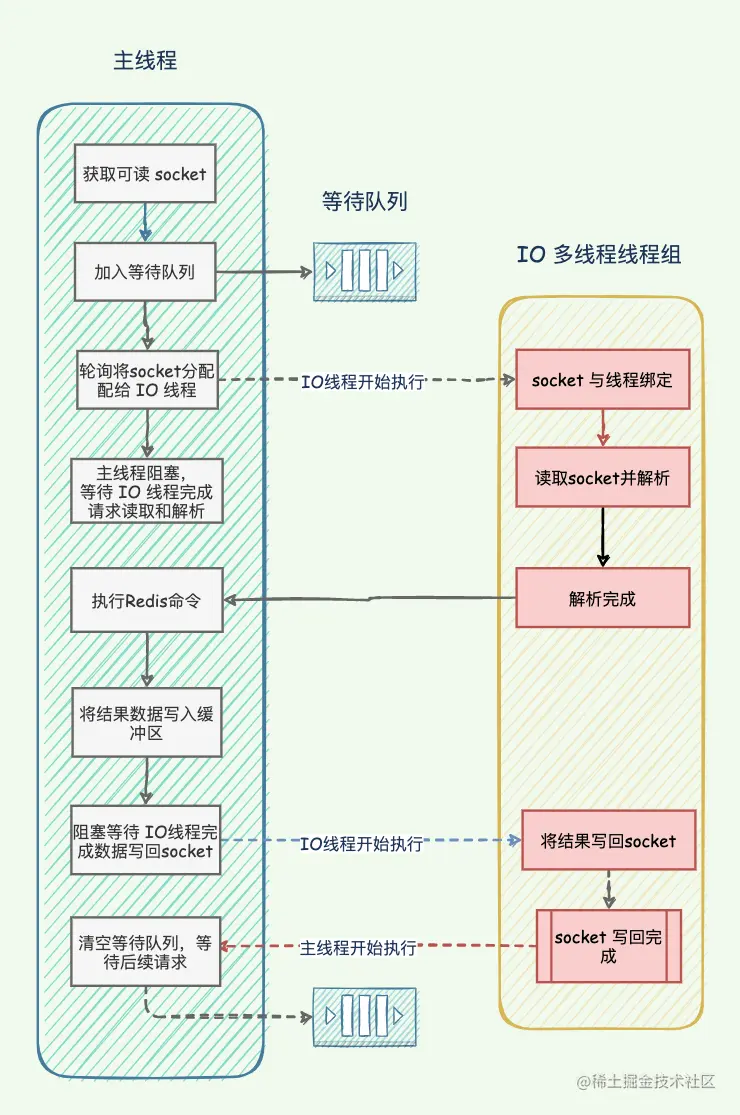
Redis 多 IO 线程模型只用来处理网络读写请求,对于 Redis 的读写命令,依然是单线程处理。
当 Redis 启用了多线程之后,里面的主线程就要负责接收事件、创建连接、执行命令。Redis 的 IO 线程就负责读写数据。
我用一个请求的处理过程来解释一下整个设计。当客户端发出请求的时候,主线程会收到一个可读的事件,于是它把对应的客户端丢到可读的客户端列表。一个 IO 线程会被安排读写这个客户端发过来的命令,并且解析好。紧接着主线程会执行 IO 线程解析好的命令,并且把响应放回到可写客户端列表里面。IO 线程负责写回响应。整个过程就结束了。
所以整个 Redis 在多线程模式下,可以看作是单线程 Reactor、单线程 Acceptor 和多线程 Handler 的 Reactor 模式。只不过 Redis 的主线程同时扮演了 Reactor 中分发事件的角色,也扮演了接收请求的角色。同时多线程 Handler 在 Redis 里面仅仅是读写数据,命令的执行还是依赖于主线程来进行的。
Redis主要瓶颈是I/O而不是CPU,但随着互联网的高速发展,在部分高并发场景,单核CPU也不见得处理得过来了,所以针对核心处理流程中的解包、发包这两个CPU耗时操作,进行了多线程优化,充分发挥多核优势
虽然说现在 Redis 读写客户端socket的 IO 改成多线程之后能够有效利用多核性能,但是大部分情况下都是不推荐使用多线程模式的(默认关闭)。道理很简单,Redis 在单线程模式下的性能就足以满足绝大多数使用场景了,那么用不用多线程已经无所谓了。
参考:
面试官:你确定 Redis 是单线程的进程吗?-有了 (zhipin.com)
Redis 6.0 新特性:带你 100% 掌握多线程模型 - 掘金 (juejin.cn)
Redis的I/O多路复用 - Vincent-yuan - 博客园 (cnblogs.com)
36|Redis 单线程:为什么 Redis 用单线程而 Memcached 用多线程? | JUST DO IT (leeshengis.com)